QNX provides a rich variety of filesystems. Like most service-providing processes in the OS, these filesystems execute outside the kernel; applications use them by communicating via messages generated by the shared-library implementation of the POSIX API.
Most of these filesystems are resource managers as described in this book. Each filesystem adopts a portion of the pathname space (called a mountpoint) and provides filesystem services through the standard POSIX API (open(), close(), read(), write(), lseek(), etc.). Filesystem resource managers take over a mountpoint and manage the directory structure below it. They also check the individual pathname components for permissions and for access authorizations.
This implementation means that:
You can seamlessly locate and connect to any service or filesystem that's been registered with the process manager. When a filesystem resource manager registers a mountpoint, the process manager creates an entry in the internal mount table for that mountpoint and its corresponding server ID (i.e. the nid, pid, chid identifiers).
This table effectively joins multiple filesystem directories into what users perceive as a single directory. The process manager handles the mountpoint portion of the pathname; the individual filesystem resource managers take care of the remaining parts of the pathname. Filesystems can be registered (i.e. mounted) in any order.
When a pathname is resolved, the process manager contacts all the filesystem resource managers that can handle some component of that path. The result is a collection of file descriptors that can resolve the pathname.
If the pathname represents a directory, the process manager asks all the filesystems that can resolve the pathname for a listing of files in that directory when readdir() is called. If the pathname isn't a directory, then the first filesystem that resolves the pathname is accessed.
For more information on pathname resolution, see the section "Pathname management" in the chapter on the Process Manager in this guide.
The many filesystems available can be categorized into the following classes:
Since it's common to run many filesystems under Neutrino, they have been designed as a family of drivers and shared libraries to maximize code reuse. This means the cost of adding an additional filesystem is typically smaller than might otherwise be expected.
Once an initial filesystem is running, the incremental memory cost for additional filesystems is minimal, since only the code to implement the new filesystem protocol would be added to the system.
The various filesystems are layered as follows:
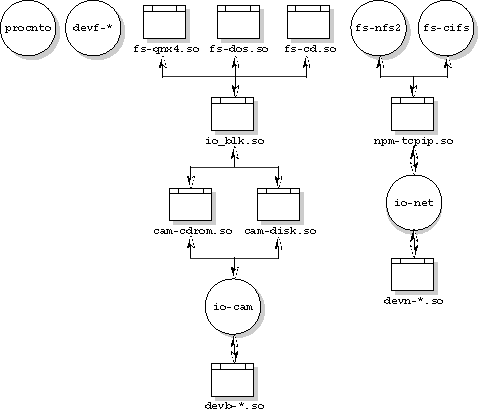
Neutrino filesystem layering.
As shown in this diagram, the filesystems, disk drivers, and io-blk are implemented as shared libraries (essentially passive blocks of code resident in memory), while io-cam is the active executable that calls into the libraries. In operation, the io-cam process starts first and invokes the block-level shared library (io-blk.so) as well as the disk driver shared libraries (devb-*). The filesystem shared libraries may be dynamically loaded later to provide filesystem interfaces and services.
A "filesystem" shared library implements a filesystem protocol or "personality" on a set of blocks on a physical disk device. The filesystems aren't built into the OS kernel; rather, they're dynamic entities that can be loaded or unloaded on demand.
For example, a removable storage device (PCCard flash card, floppy disk, removable cartridge disk, etc.) may be inserted at any time, with any of a number of filesystems stored on it. While the hardware the driver interfaces to is unlikely to change dynamically, the on-disk data structure could vary widely. The dynamic nature of the filesystem copes with this very naturally.
Most of the filesystem shared libraries ride on top of the Block I/O module (io-blk). This module also acts as a resource manager and exports a block-special file for each physical device. For a system with two hard disks the default files would be:
These files represent each raw disk and may be accessed using all the normal POSIX file primitives (open(), close(), read(), write(), lseek(), etc.). The io-blk module in Neutrino can support a 64-bit offset on seek, allowing access to disks with greater than 9 exabytes (2^63 bytes).
Neutrino complies with the de facto industry standard for partitioning a disk. This allows a number of filesystems to share the same physical disk. Each partition is also represented as a block-special file, with the partition type appended to the filename of the disk it's located on. In the above "two-disk" example, if the first disk had a QNX partition and a DOS partition, while the second disk had only a QNX partition, then the default files would be:
The following list shows some of the partition types currently used:
| Type | Filesystem |
|---|---|
| 1 | DOS (12-bit FAT) |
| 4 | DOS (16-bit FAT; partitions <32M) |
| 5 | DOS Extended Partition (enumerated but not presented) |
| 6 | DOS 4.0 (16-bit FAT; partitions >=32M) |
| 7 | OS/2 HPFS |
| 7 | Previous QNX version 2 (pre-1988) |
| 8 | QNX 1.x and 2.x ("qny") |
| 9 | QNX 1.x and 2.x ("qnz") |
| 11 | DOS 32-bit FAT; partitions up to 2047G |
| 12 | Same as Type 11, but uses Logical Block Address Int 13h extensions |
| 14 | Same as Type 6, but uses Logical Block Address Int 13h extensions |
| 15 | Same as Type 5, but uses Logical Block Address Int 13h extensions |
| 77 | QNX POSIX partition |
| 78 | QNX POSIX partition (secondary) |
| 79 | QNX POSIX partition (secondary) |
| 99 | UNIX |
| 131 | Linux (Ext2) |
The io-blk shared library implements a buffer cache that all filesystems inherit. The buffer cache attempts to store frequently accessed filesystem blocks in order to minimize the number of times a system has to perform a physical I/O to the disk.
Read operations are synchronous; write operations are usually asynchronous. When an application writes to a file, the data enters the cache, and the filesystem manager immediately replies to the client process to indicate that the data has been written. The data is then written to the disk as soon as possible.
Critical filesystem blocks such as bitmap blocks, directory blocks, extent blocks, and inode blocks are written immediately and synchronously to disk (these critical blocks bypass the normal write mechanism, including the elevator seeking).
Applications can modify write behavior on a file-by-file basis. For example, a database application can cause all writes for a given file to be performed synchronously. This would ensure a high level of file integrity in the face of potential hardware or power problems that might otherwise leave a database in an inconsistent state.
POSIX defines the set of services a filesystem must provide. However, not all filesystems are capable of delivering all those services.
The following chart highlights some of the POSIX-defined capabilities and indicates if the filesystems support them:
| Capability | Image | RAM | QNX4 | DOS | CD-ROM | Flash | NFS | CIFS | Ext2 |
|---|---|---|---|---|---|---|---|---|---|
| Access date | no | yes | yes | yes^* | yes^** | no | yes | no | yes |
| Modification date | no | yes | yes | yes | yes^** | yes | yes | yes | yes |
| Status change date | no | yes | yes | no | yes^** | yes | yes | no | yes |
| Filename length | 255 | 255 | 48 | 8.3/255^+ | 32/128/255^# | 255 | ^++ | ^++ | 255 |
| User permissions | yes | yes | yes | no | yes^** | yes | yes^++ | yes^++ | yes |
| Group permissions | yes | yes | yes | no | yes^** | yes | yes^++ | yes^++ | yes |
| Other permissions | yes | yes | yes | no | yes^** | yes | yes^++ | yes^++ | yes |
| Directories | no | no | yes | yes | yes | yes | yes | yes | yes |
| Hard links | no | no | yes | no | no | no | yes^++ | no | yes |
| Soft links | no | no | yes | no | yes^** | yes | yes^++ | no | yes |
| Decompression on read | no | no | no | no | no | yes | no | no | no |
Every QNX system image provides a simple read-only filesystem that presents the set of files built into the OS image.
Since this image may include both executables and data files, this filesystem is sufficient for many embedded systems. If additional filesystems are required, they would be placed as modules within the image where they can be started as needed.
Every QNX system also provides a simple RAM-based "filesystem" that allows read/write files to be placed under /dev/shmem.
This RAM filesystem finds the most use in tiny embedded systems where persistent storage across reboots isn't required, yet where a small, fast, temporary-storage filesystem with limited features is called for.
The filesystem comes for free with procnto and doesn't require any setup. You can simply create files under /dev/shmem and grow them to any size (depending on RAM resources).
Although the RAM filesystem itself doesn't support hard or soft links or directories, you can create a link to it by utilizing process manager links. For example, you could create a link to a RAM-based /tmp directory:
ln -sP /dev/shmem /tmp
This tells procnto to create a process manager link to /dev/shmem known as "/tmp." Application programs can then open files under /tmp as if it were a normal filesystem.
| In order to minimize the size of the RAM filesystem code inside the process manager, this filesystem specifically doesn't include "big filesystem" features such as file locking and directory creation. |
The QNX4 filesystem (fs-qnx4.so) is a high-performance filesystem that shares the same on-disk structure as QNX 4.
The QNX4 filesystem implements an extremely robust design, utilizing an extent-based, bitmap allocation scheme with fingerprint control structures to safeguard against data loss and to provide easy recovery. Features include:
For more information, see the technical note "The QNX4 Filesystem" in the Technotes section in the QNX 6 online docset.
The DOS Filesystem, fs-dos.so, provides transparent access to DOS disks, so you can treat DOS filesystems as though they were POSIX filesystems. This transparency allows processes to operate on DOS files without any special knowledge or work on their part.
The structure of the DOS filesystem on disk is old and inefficient, and lacks many desirable features. Its only major virtue is its portability to DOS and Windows environments. You should choose this filesystem only if you need to transport DOS files to other machines that require it. Consider using the QNX Filesystem alone if DOS file portability isn't an issue or in conjunction with the DOS Filesystem if it is.
If there's no DOS equivalent to a POSIX feature, fs-dos.so will either return an error or a reasonable default. For example, an attempt to create a link() will result in the appropriate errno being returned. On the other hand, if there's an attempt to read the POSIX times on a file, fs-dos.so will treat any of the unsupported times the same as the last write time.
The fs-dos.so program supports both floppies and hard disk partitions from DOS version 2.1 to Windows 98 with long filenames.
DOS terminates each line in a text file with two characters (CR/LF), while POSIX (and most other) systems terminate each line with a single character (LF). Note that fs-dos.so makes no attempt to translate text files being read. Most utilities and programs won't be affected by this difference.
Note also that some very old DOS programs may use a Ctrl -Z (^Z) as a file terminator. This character is also passed through without modification.
In DOS, a filename cannot contain any of the following characters:
/ \ [ ] : * | + = ; , ?
An attempt to create a file that contains one of these invalid characters will return an error. DOS (8.3 format) also expects all alphabetical characters to be uppercase, so fs-dos.so maps these characters to uppercase when creating a filename on disk. But it maps a filename to lowercase by default when returning a filename to a QNX application, so that QNX users and programs can always see and type lowercase. Or, it supports the Windows 95 style of capitalizing only the first letter of the filename (via the sfn=sfn_mode option).
You can specify how you want fs-dos.so to handle long filenames (via the lfn=lfn_mode option):
If you use the ignore option, you can specify whether or not to truncate filename characters beyond the 8.3 limit.
DOS uses the concept of a volume label, which is an actual directory entry in the root of the DOS filesystem. To distinguish between the volume label and an actual DOS file, fs-dos.so reports the volume label as a name-special file and will optionally place an equal sign (=) as the first character of the volume name.
DOS doesn't support all the permission bits specified by POSIX. It has a READ_ONLY bit in place of separate READ and WRITE bits; it doesn't have an EXECUTE bit. When a DOS file is created, the DOS READ_ONLY bit will be set if all the POSIX WRITE bits are off. When a DOS file is accessed, the POSIX READ bit is always assumed to be set for user, group, and other.
Since you can't execute a file that doesn't have EXECUTE permission, fs-dos.so has an option that lets you specify how to handle the POSIX EXECUTE bit for executables.
Although the DOS file structure doesn't support user IDs and group IDs, fs-dos.so (by default) won't return an error code if an attempt is made to change them. An error isn't returned because a number of utilities attempt to do this and failure would result in unexpected errors. The approach taken is "you can change anything to anything since it isn't written to disk anyway."
The posix= options let you set stricter POSIX checks and enable POSIX emulation. For example, in POSIX mode, an error of EINVAL is flagged for attempts to do any of the following:
The CD-ROM filesystem provides transparent access to CD-ROM media, so you can treat CD-ROM filesystems as though they were POSIX filesystems. This transparency allows processes to operate on CD-ROM files without any special knowledge or work on their part.
The fs-cd.so manager implements the ISO 9660 standard as well as a number of extensions, including Rock Ridge (RRIP), Joliet (Microsoft), and multisession (Kodak Photo CD, enhanced audio).
The flash filesystem drivers implement a POSIX-like filesystem on NOR flash memory devices. The flash filesystem drivers are standalone executables that contain both the flash filesystem code and the flash device code. There are versions of the flash filesystem driver for different embedded systems hardware as well as PCMCIA memory cards.
The naming convention for the drivers is devf-system, where system describes the embedded system. For example, the devf-800fads driver is for the 800FADS PowerPC evaluation board.
To find out what flash devices we currently support, please refer to the following sources:
Along with the pre-built flash filesystem drivers, including the "generic" driver (devf-generic), provide the libraries and source code needed to build custom flash filesystem drivers for different embedded systems. For information on how to do this, see the chapter on customizing a flash filesystem driver in the Building Embedded Systems book.
The flash filesystem drivers support one or more logical flash drives. Each logical drive is called a socket, which consists of a contiguous and homogeneous region of flash memory. For example, in a system containing two different types of flash device at different addresses, where one flash device is used for the boot image and the other for the flash filesystem, each flash device would appear in a different socket.
Each socket may be divided into one or more partitions. Two types of partitions are supported: raw partitions and flash filesystem partitions.
A raw partition in the socket is any partition that doesn't contain a flash filesystem. The flash filesystem driver doesn't recognize any filesystem types other than the flash filesystem. A raw partition may contain an image filesystem or some application-specific data.
The flash filesystem will make accessible through a raw mountpoint (see below) any partitions on the flash that aren't flash filesystem partitions. Note that the flash filesystem partitions are available as raw partitions as well.
A flash filesystem partition contains the POSIX-like flash filesystem, which uses a QNX proprietary format to store the filesystem data on the flash devices. This format isn't compatible with either the Microsoft FFS2 or PCMCIA FTL specification.
The flash filesystem allows files and directories to be freely created and deleted. It recovers space from deleted files using a reclaim mechanism similar to garbage collection.
When you start the flash filesystem driver, it will by default mount any partitions it finds in the socket. Note that you can specify the mountpoint using mkefs or flashctl (e.g. /flash).
| Mountpoint | Description |
|---|---|
| /dev/fsX | raw mountpoint socket X |
| /dev/fsXpY | raw mountpoint socket X partition Y |
| /fsXpY | filesystem mountpoint socket X partition Y |
| /fsXpY/.cmp | filesystem compressed mountpoint socket X partition Y |
The flash filesystem supports many advanced features, such as POSIX compatibility, multiple threads, background reclaim, fault recovery, transparent decompression, endian-awareness, wear-leveling, and error-handling.
The flash filesystem supports the standard POSIX functionality (including long filenames, access privileges, random writes, truncation, and symbolic links) with the following exceptions:
These design compromises allow the flash filesystem to remain small and simple, yet include most features normally found with block device filesystems.
The flash filesystem stores files and directories as a linked list of extents, which are marked for deletion as they're deleted or updated. Blocks to be reclaimed are chosen using a simple algorithm that finds the block with the most space to be reclaimed while keeping level the amount of wear of each individual block. This wear-leveling increases the MTBF (mean time between failures) of the flash devices, thus increasing their longevity.
The background reclaim process is performed when there isn't enough free space. The reclaim process first copies the contents of the reclaim block to an empty spare block, which then replaces the reclaim block. The reclaim block is then erased. Unlike rotating media with a mechanical head, proximity of data isn't a factor with a flash filesystem, so data can be scattered on the media without loss of performance.
The flash filesystem has been designed to minimize corruption due to accidental loss-of-power faults. Updates to extent headers and erase block headers are always executed in carefully scheduled sequences. These sequences allow the recovery of the flash filesystem's integrity in the case of data corruption. With properly designed hardware for power faults, flash write transactions can be guaranteed to be finished when a power fault occurs (as long as there's just enough power left to commit a 10-microsec write cycle). Note that even rename operations are guaranteed atomic -- even through loss-of-power faults -- so you can safely use rename operations to update application code with the flash filesystem.
When the flash filesystem driver is started, it scans the state of every extent header on the media (in order to validate its integrity) and takes appropriate action, ranging from a simple block reclamation to the erasure of dangling extent links. This process is merged with the normal mount procedure of the flash filesystem in order to achieve optimal bootstrap timings.
The flash filesystem inherently supports transparent decompression of files that have been compressed using the flashcmp utility. The utility supports two compression algorithms:
The utility can reduce most executables to about a third of their uncompressed size.
| You can also use the deflate/inflator pair of utilities to compress/decompress files for any filesystem, including flash. For example, you might have a block-oriented flash device, in which case you'd be using a devb-* driver rather than the flash filesystem. |
Compressed files can be manipulated with standard utilities such as cp or ftp -- they can display their compressed and uncompressed size with the ls utility if used with the proper mountpoint. These features make the management of a compressed flash filesystem seamless to a systems designer.
As flash hardware wears out, its write state-machine may find that it can't write or erase a particular bit cell. When this happens, the error status is propagated to the flash driver so it can take proper action (i.e. mark the bad area and try to write/erase in another place).
This error-handling mechanism is transparent. Note that after several flash errors, all writes and erases that fail will eventually render the flash read-only. Fortunately, this situation shouldn't happen before several years of flash operation. Check your flash specification and analyze your application's data flow to flash in order to calculate its potential longevity or MTBF.
The flash filesystem is endian-aware, making it portable across different platforms. The optimal approach is to use the mkefs utility to select the target's endian-ness.
The flash filesystem supports all the standard POSIX utilities such as ls, mkdir, rm, ln, mv, and cp. There are also some QNX utilities for managing the flash filesystem:
The flash filesystem supports all the standard POSIX I/O functions such as open(), close(), read(), and write(). Special functions such as erasing are supported using the devctl() function.
The Network File System (NFS) allows a client workstation to perform transparent file access over a network. It allows a client workstation to operate on files that reside on a server across a variety of operating systems. Client file access calls are converted to NFS protocol requests, and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and sends a response back to the client.
The Network File System operates in a stateless fashion by using remote procedure calls (RPC) and TCP/IP for its transport. Therefore, to use fs-nfs2 you'll also need to run the TCP/IP client for Neutrino.
Any POSIX limitations in the remote server filesystem will be passed through to the client. For example, the length of filenames may vary across servers from different operating systems. NFS (version 2) limits filenames to 255 characters; mountd (version 1) limits pathnames to 1024 characters.
| Although NFS (version 2) is older than POSIX, it was designed to emulate UNIX filesystem semantics and happens to be relatively close to POSIX. |
Formerly known as SMB, the Common Internet File System (CIFS) allows a client workstation to perform transparent file access over a network to a Windows 98 or NT system, or a UNIX system running an SMB server. Client file access calls are converted to CIFS protocol requests and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and sends a response back to the client.
| The CIFS protocol makes no attempt to conform to POSIX. |
The fs-cifs module uses TCP/IP for its transport. Therefore, to use fs-cifs (SMBfsys in QNX 4), you'll also need to run the TCP/IP client for Neutrino.
The Ext2 filesystem (fs-ext2.so) provides transparent access to Linux disk partitions. This implementation supports the standard set of features found in Ext2 versions 0 and 1.
Sparse file support is included in order to be compatible with existing Linux partitions. Other filesystems can only be "stacked" read-only on top of sparse files. There are no such restrictions on normal files.
If an Ext2 filesystem isn't unmounted properly, a filesystem checker is usually responsible for cleaning up the next time the filesystem is mounted. Although the fs-ext2.so module is equipped to perform a quick test, it automatically mounts the filesystem as read-only if it detects any significant problems (which should be fixed using a filesystem checker).
QNX provides two types of virtual filesystems:
Neutrino's package filesystem component is a virtual filesystem manager that presents a customized view of a set of files and directories to a client. The actual files are present on some medium (e.g. a server's hard disk) -- the package filesystem presents a "virtual" view of selected files to the client.
This can be useful in a networked environment, where a centralized server maintains a separate package of files for each client machine. Each client may want to see their own custom versions of certain files or unique combinations of files in a package.
Traditionally, you would achieve this either by copying all the files for all the packages into directories, with one directory per machine, or by creating various symbolic links. These inefficient approaches don't scale well for larger networks, and can waste a lot of time whenever a change-of-version operation is required.
By capitalizing on Neutrino's pathname space and resource manager concepts, the package filesystem manager alleviates these problems.
A package consists of a number of files and directories that are related to each other by virtue of being part of a product or of a particular release. For example, the QNX OS, including its binary files and online documentation, is considered a package. A set of updates (called a patch) to the OS might contain only selected files and documentation (i.e. the files that have changed); this would be a different package.
The purpose of the package filesystem is to manage these packages in such a way that various nodes can pick and choose which particular packages they want to use. For example, one node might be an x86 box running, say, Patch B of a certain release, while another node might be a PowerPC box running Patch C.
Since these two machines are different CPU types, we need to give each of them not only different types of executables in their /bin directories (one set of x86 executables and one set of PowerPC executables), but also different contents based on the desired version of the software and patch levels.
In a nutshell, the package filesystem presents, on each node, a virtual filesystem that contains only selected files from the master package database. The selection is controlled by a definition file that indicates:
The advantage of a single definition file is clear: When the time comes to change the package lineup on a particular node, this can be accomplished by a simple (and fast!) change to the definition file.
Inflator is a resource manager that sits in front of other filesystems and inflates files that were previously deflated (using the deflate utility).
The inflator utility is typically used when the underlying filesystem is a flash filesystem. Using it can almost double the effective size of the flash memory.
If a file is being opened for a read, inflator attempts to open the file itself on an underlying filesystem. It reads the first 16 bytes and checks for the signature of a deflated file. If the file was deflated, inflator places itself between the application and the underlying filesystem. All reads return the original file data before it was deflated.
From the application's point of view, the file appears to be uncompressed. Random seeks are also supported. If the application does a stat() on the file, the size of the inflated file (the original size before it was deflated) is returned.